
Divyanshu Goyal
Applied Scientist at Adobe
Applied Scientist at Adobe and multimodal researcher focused on training and evaluating vision-language models. I hold an M.S. in Computer Science (Machine Learning) from Georgia Tech. My work spans VLM training, multimodal reasoning, and LLM pretraining,turning frontier research into systems that ship to production.
About Me
Education
M.S. in Computer Science
Georgia Institute of Technology
Machine Learning
B.E. in Computer Science
Birla Institute of Technology and Sciences, Pilani
M.Sc. in Mathematics
Birla Institute of Technology and Sciences, Pilani
Expertise
Tools & Languages
Publications & Patents
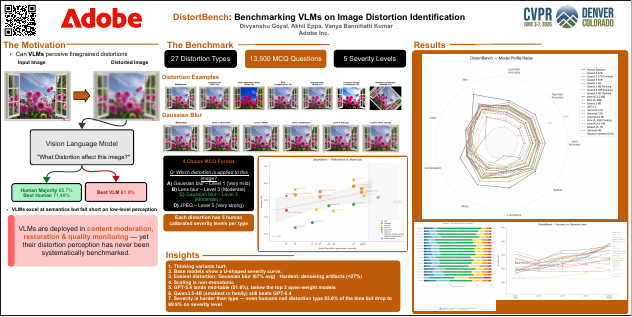
DistortBench: Benchmarking Vision Language Models on Image Distortion Identification
Divyanshu Goyal, Akhil Eppa, Vanya Bannihatti Kumar
Cultural Adaptation of Images Using Generative Artificial Intelligence
Akhil Eppa, Mayank Anand, Divyanshu Goyal
Guiding Language Translation with Translation Documents Using Machine Learning
Divyanshu Goyal, Akhil Eppa, Mayank Anand
Curiosity-Driven LLM-as-a-judge for Personalized Creative Judgment
Vanya Bannihatti Kumar, Divyanshu Goyal, Akhil Eppa, Neel Bhandari
Systems and Methods to Provide Parameter-Efficient Fine-Tuned Models
Yuanyou Wang, Naveen Vangala, Mayank Anand, Kunal Kumar Jain, Jose Mathew, Eapen Jose, Divyanshu Goyal, Asmita Chihnara, Arif Abdullah, Anand Dantu
Brand-Aligned Marketing Content Generation Using Structured Brand Data and Generative Models
Divyanshu Goyal, Mayank Anand, Jose Mathew
Experience
Applied Scientist
/Adobe, San Jose, CAJune 2021:Present
Vision-Language Model Training & Evaluation
- Fine-tuned a Gemma-3-12B vision-language model with LoRA across 8× H100 GPUs (DDP, bfloat16, Flash Attention 2 + Liger kernels) for large-scale marketing-quality assessment.
- Pioneered an "observable injection" technique that grounds VLM quality reasoning in 14+ computed pixel-level metrics (sharpness, exposure, color balance), yielding an interpretable scorer at Pearson r ≈ 0.88 and MAE 0.77 that outperforms GPT-5.4 (MAE 1.34) and Claude Opus 4.7 (MAE 1.95).
- Built the MQCore evaluation benchmark (inspired by DCLM CORE) and a fault-tolerant async annotation pipeline processing 100+ images/min over the 700K-image KADIS corpus.
Multimodal Research & Benchmarking
- Authored DistortBench (CVPR FGVC13 Workshop 2026):a 13.5K-question diagnostic benchmark spanning 27 distortion types, 6 perceptual categories, and 5 severity levels.
- Evaluated 18+ frontier VLMs (GPT-5.4, Claude Sonnet 4.6, Qwen, InternVL, Gemma) with bootstrap CIs and balanced-accuracy metrics, exposing low-level perception as a major weakness:top model 61.9% vs. 65.7% human baseline.
- Created a curiosity-driven LLM-as-a-judge framework for personalized creative evaluation using Bayesian surprise (arXiv 2025):+23% F1 and +38% correlation over baselines.
Production Multimodal Systems & Agents
- Architected the Unified Brand Service (90K+ LOC across 3 global regions) powering Adobe GenStudio:multimodal brand-DNA extraction, RAG-based retrieval, and GPT-4-Vision content validation.
- Built a multimodal agent that drives Adobe Photoshop from natural language via a 49-tool observe-think-act loop with vision grounding and an iterative quality-critic refinement layer.
- Led the foundational prototype of Adobe GenStudio for Performance Marketing (Oct 2024, now serving Fortune 500 clients including Microsoft and AT&T) and invented patented VLM pipelines for cross-cultural image adaptation and constrained translation (US Patents 2026).
Machine Learning Engineer
/Adobe, Bangalore, IndiaJuly 2016:August 2019
ML Infrastructure & Serving
- Co-engineered Adobe's ML inference platform:3,500 QPS/node at 0.3–0.6ms latency (p99).
- Designed GC-free async event pipeline using LMAX Disruptor, eliminating back-pressure under peak load.
- Built custom model lifecycle management platform:versioned deployment, monitoring, and staged rollout across environments.
Projects
VibeNanoChat:Training GPT-2 Scale LLMs from Scratch
A from-scratch framework for pretraining, scaling, and evaluating GPT-2 scale language models:featuring depth-parameterized scaling laws, a custom distributed Muon optimizer, and a 35+ benchmark evaluation suite.
Marketing Quality Vision Language Model
Built a complete MLOps system for training vision-language models to assess marketing content quality, featuring novel observable injection and Photoshop edit evaluation capabilities.
Adobe GenStudio for Performance Marketing
Built the founding prototype and pitched it to Adobe leadership, leading to the launch of a generative-AI platform for creating on-brand marketing content at scale.